Doximity GPT vs OpenEvidence | Which Delivers for Doctors?
A look at the first serious duel of medical LLMs

This week we entered a new era: doctors now have not one, but two purpose-built large language models at their fingertips. OpenEvidence and Doximity GPT mark the first serious wave of medical LLMs, and they’re already changing how we find answers at the point of care.
While many of my peers still lean on ChatGPT for clinical questions, few realize that these physician-specific tools now exist. With Doximity’s launch of the latest DoxGPT, I decided to put it head-to-head against OpenEvidence.
Before my results, I spent some time just living with both platforms …clicking, poking, and seeing how they felt in the flow of daily work.
General Impressions
Interface. The first thing that struck me was the interface. Both are clean and uncluttered, with the prompt box taking center stage. That’s exactly how it should be, an open space that feels ready for work.
Specialty specific — or not. DoxGPT made the experience feel personal. Because Doximity knows my specialty, it surfaced suggested prompts around pediatric GI —things I might realistically want to explore. Some of them made me realize I didn’t have as confident an answer as I thought, which pulled me deeper into the model. OpenEvidence, by contrast, doesn’t offer this. Instead, it greeted me with a flashing pitch for something. It felt like walking through Las Vegas when all I wanted was an answer. That sense of specialty awareness matters. DoxGPT’s prompts reminded me that this tool “knows” who I am in a way that felt useful, not intrusive. OpenEvidence, on the other hand, doesn’t allow me to specify a pediatric subspecialty in my profile. This is a glaring miss for a product built for physicians.
CME. One advantage OpenEvidence does bring is CME credit, which I suspect will become a standard feature of these platforms. And while DoxGPT is experimenting with peer review layered on top of answers, I didn’t see it in action during my comparison. This seems like a glimpse at where it might be headed rather than something fully realized today.
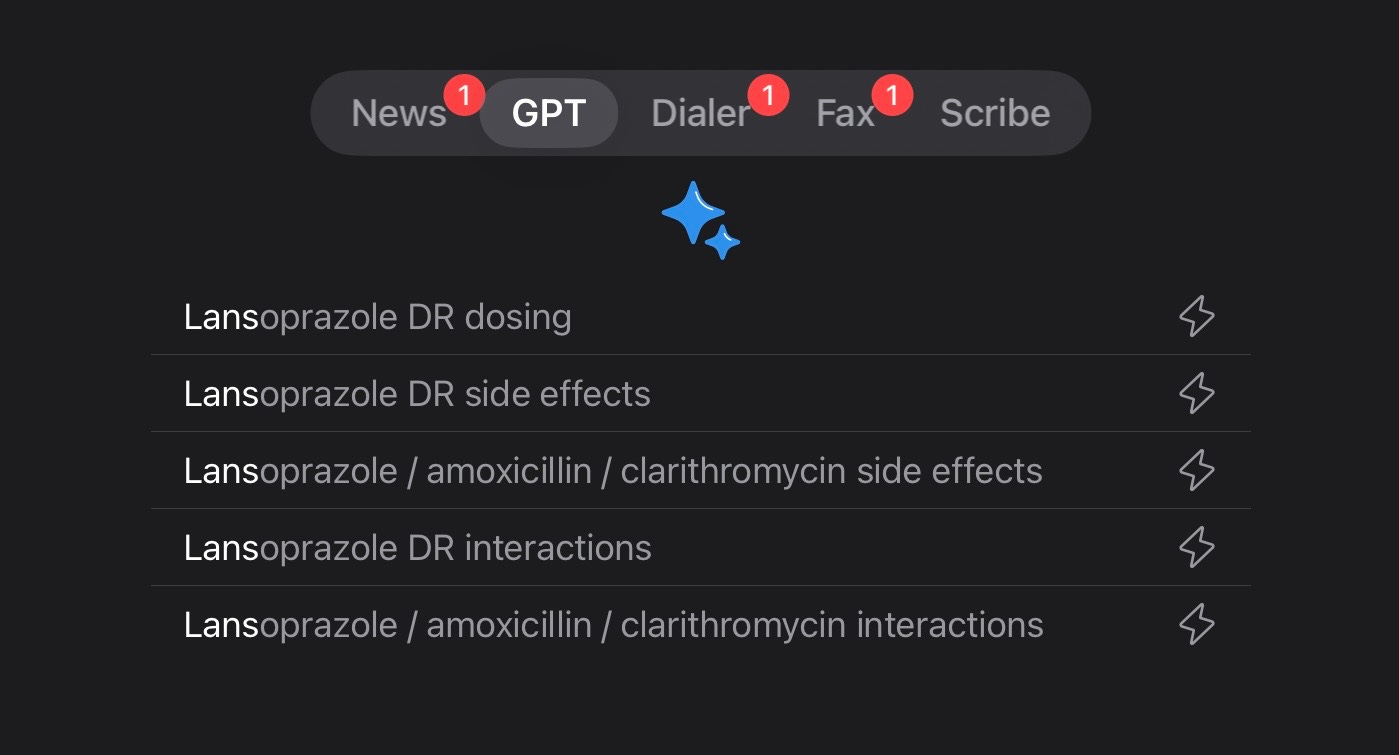
Flawless dosing recall. DoxGPT does bring a novel element that isn’t immediately obvious when you use it. If you type in the name of a drug, predictive reasoning immediately populates a pull-down with your drug (you’ll see a little lightening bolt⚡️next to the pull down result). Click on one of them to see the response. This is important: The response is drawn from a drug database of over 3200 drug monographs including information on dosing, interactions and side effects. So there’s no risk that AI could hallucinate as you’re writing your prescription. It’s both an LLM and a database.
Speed. OpenEvidence loaded faster on my iPad Pro over AT&T 5G+, though its responses were a bit shorter.
Putting Them to the Test
To really pressure test the models, I asked a question central to my practice:
PPI dosing for children with eosinophilic esophagitis.
Most readers probably don’t care about the pharmacologic nuances here, but a few contrasts stood out when I put the two models side by side. While both were directionally correct, the differences were interesting and reflect the fact that there isn't one 'ground truth' for LLMs despite access to the same literature. This reality reflects the potential importance of a human-in-the-loop, or at least an understanding of limitations by the user.
Key Differences
Dose cap. OpenEvidence caps omeprazole at 20 mg BID. Safe, but risks under dosing bigger kids and adolescents. DoxGPT allows up to 40 mg per dose which closer to guideline-based practice. When I pushed OE in follow-up around higher dosing, it acknowledged that it is acceptable.
BID vs QD. Evidence shows BID dosing outperforms QD for histologic response. OpenEvidence names the rationale; DoxGPT operationalizes it for me.
Follow-up & remission target. DoxGPT lays out an 8 week pathway of induction, repeat endoscopy with biopsies, remission defined as <15 eos/HPF, then step-down. OpenEvidence mentions follow-up, but in a less directive way.
Maintenance. DoxGPT cites data from pediatric studies, showing high rates of remission with step-down therapy. OpenEvidence notes that maintenance exists, but doesn’t quantify outcomes.
Alternatives. While I didn't explicitly ask for it, DoxGPT proactively mentions topical steroids, dietary therapy and dupilumab (now FDA-approved for ages 1–11 y), which is helpful. OpenEvidence omits this newer regulatory context. Both tools could have mentioned an approved budesonide oral suspension that we sometimes use, but didn’t
Verdict
When I step back and think about which tool I’d actually want open on my desk, OE is a solid option but the edge for me goes to DoxGPT.
Three elements tip the balance for me:
Doximity knows who I am. Because the platform recognizes me as a pediatric gastroenterologist, it frames the experience in a way that feels tuned to my practice. That specialty awareness isn’t just a nice-to-have — it makes the model feel like it was built with me in mind.
The way DoxGPT presents its answers is more usable. The editorial design is cleaner, the steps are easier to follow, and the content feels more like a roadmap than a block of text. The conclusions are delivered up front and they (like me) like tables. In a world where I’m often skimming between patients, readability matters.
There’s the promise of something bigger. Doximity is hinting at a peer review layer. And the idea that my colleagues could validate or refine what the model surfaces becomes key when you look at the differences in response that LLMs can generate. If they can pull that off, it could be the first time a medical LLM feels less like a black box and more like a collaborative instrument.
OpenEvidence is a solid option for clinicians ... CME is a clear differentiator. But if you ask me which of these two I’d rely on in practice today, my vote goes to DoxGPT.
I'll also add that these models are iterating so fast that by the time you read this, the findings I discussed earlier this week around this narrow prompt may already been adjusted for. And that's the way it should be. These discussions among users are central to a fertile culture of innovation in healthcare. As OE and DoxGPT compete and evolve around our needs, the doctors can only win.
I’d love to hear from others experimenting with these platforms:
What do you think they get right?
Where do they miss the mark?
And how do you see physician-specific LLMs fitting into your practice?
This is a slightly modified version of an article that appeared in LinkedIn earlier this week. In the past I served on Doximity’s medical advisory board.
Been playing around with them for a couple of months now.
Note of caution: seeing some real misinterpretations of hte data/hallucinations esp in OE lately.
Even when pushed with specific citations it dug in its heels and would not budge from OBVIOUSLY erroneous interpretations, some of which appear DANGEROUS.
these things are really NOT ready for prime time UNLESS you remain ON GUARD. I like the peer reviewed idea. It may NOT be optional!
Thank you very much for a great analysis. I will be sharing this. I’m at AAFP’s FMX now and many of us are discussing this.